The New Vision 1: Open-Vocabulary Object Detection

By Ilja Bakx
Date
Jun 24, 2025

The Shift to Open-Vocabulary Object Detection
The field of computer vision has been profoundly transformed by the advent of deep learning, with object detection standing as one of its most critical and widely applied tasks. From autonomous driving to medical imaging, the ability of machines to locate and classify objects in visual data is fundamental. However, for many years, the dominant paradigm has operated under a significant constraint known as the "closed-world" or "closed-set" assumption. Over the next 3 blog posts we will dive deeper into OVD, in this first post we will the highlight the limitiations of the traditional approach & introduce OVD and the most common framworks that make this possible.
From Closed-Set to Open-World: Defining the Problem Space and Its Significance
Traditional object detectors, including highly successful architectures like the You Only Look Once (YOLO) family and Faster R-CNN, are designed to identify objects from a finite, predefined set of categories. The vocabulary of these models is "closed," meaning it is strictly limited to the classes present in their training datasets, such as the 80 categories in COCO or the 600 in Objects365. The primary bottleneck of this approach is the immense cost and labor associated with data annotation. To expand the model's vocabulary and to teach it to recognize a new object, one must collect and manually annotate thousands of images with bounding boxes for that specific category. Scaling this process to the vast diversity of objects in the real world is practically infeasible; extending a detector from 600 to 60,000 categories would require a hundred-fold increase in resources, placing a truly versatile detector out of reach.
In response to this fundamental limitation, the field has shifted towards a more flexible and scalable paradigm: Open-Vocabulary Object Detection (OVD). OVD is formally defined as the task of detecting objects from an unbounded, or "open," vocabulary, which can include novel categories that were not seen during the training phase. Instead of being limited to a fixed set of class IDs, an OVD model can detect objects specified by arbitrary human language inputs, such as category names or descriptive phrases, provided at inference time without any need for model retraining. This capability makes detectors far more general, practical, and easily extendable to new domains and applications.
It is crucial to distinguish OVD from related concepts. Zero-Shot Detection (ZSD) also aims to detect unseen classes, but early ZSD methods often struggled to achieve practical performance because they relied solely on weak semantic signals from word embeddings to infer visual properties. OVD, powered by modern Vision-Language Models, has proven more robust. Furthermore, OVD is a key enabling component of the even more ambitious goal of Open-World Object Detection (OWOD). While OVD focuses on detecting novel objects from a user-provided vocabulary, OWOD aims to build systems that can not only detect known and novel classes but also explicitly identify completely unknown objects as "unknown" and incrementally learn these new categories over time.
The Role of Vision-Language Pre-training: How Models like CLIP Enable Zero-Shot Capabilities
The breakthrough that unlocked the potential of OVD was the development of large-scale Vision-Language Models (VLMs), most notably CLIP (Contrastive Language-Image Pre-training) and ALIGN. These models are not trained on meticulously curated object detection datasets but on massive, noisy collections of image-text pairs scraped from the internet, numbering in the hundreds of millions or billions.

The core mechanism behind these VLMs is contrastive learning. The training process involves two main components: an image encoder (e.g., a Vision Transformer or ViT) and a text encoder (e.g., a Transformer). For a given batch of image-text pairs, the model encodes both the images and the text into a shared, high-dimensional embedding space. The training objective is to maximize the cosine similarity (a measure of vector alignment) between the embeddings of corresponding image-text pairs (e.g., an image of a dog and the caption "a photo of a dog") while simultaneously minimizing the similarity between all non-corresponding pairs in the batch. Through this process, the model learns a rich, multi-modal semantic space where visual concepts are aligned with their natural language descriptions. This learned alignment is the foundation of the model's powerful zero-shot recognition capability: it can identify whether an image matches a text description even if it has never seen that specific object-caption combination during training.

However, a fundamental challenge arises when adapting these powerful image-level models to the task of object detection. This is often referred to as a "domain shift" or "modality gap". CLIP is trained to match an entire image to a holistic text description. Object detection, in contrast, is a fine-grained, region-level task that requires aligning specific image regions with corresponding text spans (e.g., identifying the pixels belonging to a "wheel" within an image of a "car"). Directly applying CLIP's image-level feature representation to classify arbitrary regions within an image leads to poor performance because the model was not explicitly trained for this kind of localized understanding. This critical discrepancy, the gap between image-level pre-training and region-level detection, is the central technical hurdle that has motivated the creation of the sophisticated OVD architectures that now dominate the field.
Fundamental Architecture: Deconstructing the Vision Encoder, Text Encoder, and Fusion Mechanisms
At its core, a modern OVD model is a sophisticated system designed to bridge the aforementioned domain shift. The fundamental architecture generally consists of three primary components, forming a dual-encoder structure with a fusion mechanism.
- Vision Encoder: This module processes the input image to extract visual features. While earlier models used Convolutional Neural Networks (CNNs) like ResNet, the state-of-the-art has largely shifted to Vision Transformers (ViTs) or their variants (e.g., Swin Transformer). The ViT splits an image into a sequence of fixed-size patches, embeds them, and processes them through a Transformer encoder, resulting in a grid of feature vectors, each representing a part of the image.
- Text Encoder: This module processes the natural language prompt, which contains the names or descriptions of the objects to be detected. It is typically a Transformer-based language model, often the text encoder from a pre-trained VLM like CLIP. It takes a text string (e.g., "a red sports car") and outputs a high-dimensional semantic embedding that captures its meaning.
- Fusion Mechanism: This is the heart of the OVD model, where the visual and linguistic information is integrated. Early or simple approaches might just concatenate the feature vectors, but modern architectures employ much more sophisticated techniques. The dominant method is cross-attention, where the features from one modality (e.g., vision) are used to "query" the features from the other modality (e.g., text), allowing the model to dynamically weigh and combine information from both sources.

The general inference process follows from this architecture. First, the model generates region proposals, potential bounding boxes where objects might be located. Then, for each proposal, it extracts a visual feature vector. This visual feature is compared against the text embeddings of all candidate classes provided in the prompt. The class whose text embedding has the highest similarity score (e.g., cosine similarity) with the region's visual feature is assigned as the label for that bounding box. The specific ways in which different models implement this fusion and classification process define their unique strengths and trade-offs, which will be explored in the next section.
Foundational Architectures in Open-Vocabulary Detection
The conceptual framework of OVD has given rise to several distinct architectural families, each representing a different philosophy for solving the core problem of adapting image-level VLMs to region-level detection. These foundational models, OWL-ViT, Grounding DINO, and YOLO-World, have set the benchmarks and defined the primary research trajectories in the field. This section provides a deep dive into the mechanics, innovations, and design principles of each.
OWL-ViT and OWLv2: Vision Transformers for Open-World Localization
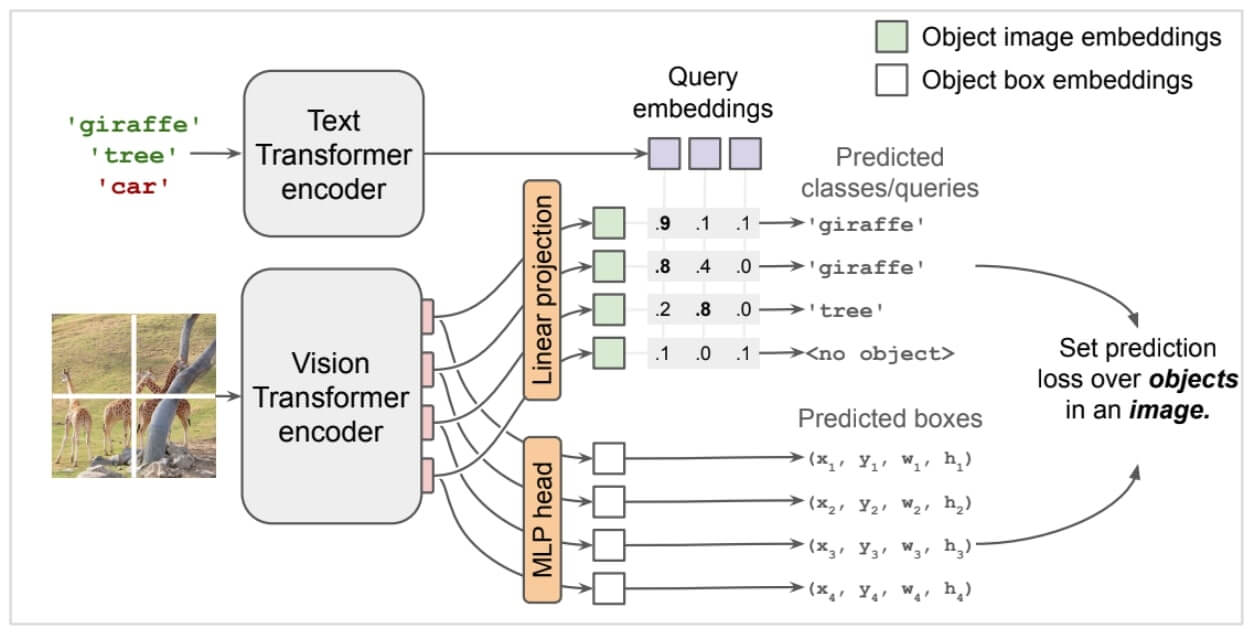
The OWL-ViT (Vision Transformer for Open-World Localization) family, developed by Google Research, represents a minimalist yet powerful approach to OVD. Its design philosophy centers on adapting a pre-trained CLIP model for the detection task with as few architectural modifications as possible, thereby preserving the rich, generalizable knowledge learned during large-scale contrastive pre-training.
OWL-ViT Architecture Deep Dive
The architecture of OWL-ViT is a direct and elegant adaptation of the CLIP framework. The process is as follows:
- CLIP Backbone: The model begins with a standard CLIP model, which consists of a ViT-based image encoder and a Transformer-based text encoder.
- Key Architectural Modification: The crucial innovation lies in how the ViT image encoder is repurposed. In a standard ViT used for image classification, the output tokens corresponding to different image patches are pooled into a single `` token, which produces one feature vector for the entire image. OWL-ViT removes this final pooling layer. This modification exposes the full grid of output tokens from the final layer of the ViT, where each token is a feature vector corresponding to a specific patch of the input image.
- Lightweight Detection Heads: Class-agnostic classification and bounding box regression heads are then attached to each of these output patch tokens. This allows the model to make a detection prediction at every spatial location in the feature grid.
- Open-Vocabulary Classification: The mechanism for open-vocabulary classification is both simple and powerful. When a user provides a text query (e.g., "a cat," "a dog"), the text encoder processes these queries to generate corresponding semantic embeddings. These text embeddings are then used directly as the weights of the classification head. Classification is performed by computing the cosine similarity between the visual feature of each patch token and the text embeddings of all query classes. The class with the highest similarity is assigned. This turns the classification head into a dynamic, query-able module capable of recognizing any object that can be described with text.
- Training: The entire model, including the pre-trained CLIP backbone and the newly added detection heads, is fine-tuned end-to-end on standard object detection datasets like COCO and OpenImages. The training uses a bipartite matching loss, similar to the DETR family of models, which finds an optimal one-to-one matching between the model's predictions and the ground-truth objects in an image.
The Leap to OWLv2: Scaling with Self-Training
While OWL-ViT established a strong baseline, its performance was ultimately constrained by the limited size and diversity of human-annotated detection datasets. The development of OWLv2 was driven by the need to overcome this data scarcity by leveraging the vast amount of weakly-supervised data available on the web.
The core innovation of OWLv2 is the OWL-ST (OWL Self-Training) recipe, a three-step process designed to scale up training data to an unprecedented level :
- Pseudo-Label Generation: A powerful, pre-trained OWL-ViT model (the "teacher") is used to generate pseudo-box annotations on a massive web-scale dataset of image-text pairs, such as WebLI, which contains approximately 10 billion images with associated alt-text. For each image, queries are generated from the alt-text (e.g., by extracting N-grams), and the teacher model detects and labels objects corresponding to these queries.
- Self-Training: A new detector (the "student," which becomes OWLv2) is then trained from scratch on this enormous dataset of machine-generated pseudo-annotations. This allows the model to learn from billions of examples, far exceeding any human-annotated dataset.
- Fine-tuning (Optional): Finally, the student model can be fine-tuned on a smaller, high-quality dataset of human annotations to further refine its performance.

This self-training approach required architectural optimizations for efficiency. OWLv2 introduced techniques like token dropping and instance selection to speed up training. A significant architectural addition was an objectness head. This is a simple classifier that predicts the likelihood that a given bounding box contains any object, regardless of its class or the text query. This objectness score allows the model to effectively filter out background proposals early in the pipeline, improving both efficiency and accuracy. The OWL-ST recipe proved immensely successful, unlocking web-scale training for OVD and setting new state-of-the-art performance benchmarks, particularly on challenging rare-class detection.
Grounding DINO: Marrying DETR with Grounded Pre-Training
Grounding DINO represents a different architectural philosophy. Instead of minimally adapting a VLM, it aims to build the most powerful open-set detector possible by deeply integrating language information into every stage of a strong, Transformer-based, closed-set detector. It "marries" the high-performance DINO (DEtection TRansformer with improved de-noising) architecture with a grounded pre-training strategy, effectively reframing object detection as a phrase grounding task: locating the image region that corresponds to a given text phrase.
Architectural Deep Dive
Grounding DINO's architecture is a dual-encoder, single-decoder model that implements a "tight fusion" strategy at three key phases :
- Backbones and Feature Extraction: The model starts with a powerful image backbone (e.g., Swin Transformer) to extract multi-scale visual features and a text backbone (e.g., BERT) to extract text features from the input prompt.
- Feature Enhancer (Neck): Before the main detection decoder, Grounding DINO employs a feature enhancer module. This consists of several layers of self-attention and cross-attention that fuse the image and text features at an early stage. This deep, early fusion allows the model to create enriched, cross-modal representations before attempting to identify objects.
- Language-Guided Query Selection (Query Initialization): A key departure from standard DETR-like models is how the object queries are initialized. In DETR, queries are typically learned embeddings that are independent of the input. In Grounding DINO, the text features are used to explicitly guide the selection of the most relevant image features to serve as the initial queries for the decoder. This ensures that the detection process is conditioned on the language prompt from the very beginning, focusing the model's attention on relevant parts of the image.
- Cross-Modality Decoder (Head): The main Transformer decoder is modified to be cross-modal. In each decoder layer, the object queries are refined by attending to both the image features (via a standard cross-attention mechanism) and the text features (via an additional text cross-attention layer). This constant injection of information from both modalities allows the decoder to progressively refine the predicted bounding boxes and class labels with a rich, fused understanding of the visual scene and the textual query.
This deep, multi-stage fusion strategy is the primary reason for Grounding DINO's exceptional performance. It has achieved state-of-the-art results on numerous benchmarks, including a remarkable 52.5 AP in a zero-shot setting on the COCO dataset, meaning it can detect COCO objects with high accuracy without ever being trained on COCO's bounding box annotations.
YOLO-World: Real-Time Open-Vocabulary Detection
While Transformer-based architectures like OWL-ViT and Grounding DINO pushed the boundaries of accuracy, their high computational cost made them impractical for many real-world applications, especially those requiring real-time performance on edge devices. YOLO-World was developed to address this efficiency gap by integrating open-vocabulary capabilities into the highly optimized and lightweight YOLO architecture.
Architectural Deep Dive
YOLO-World's design prioritizes speed and practicality, leveraging a CNN-based backbone for efficiency :
- Core Components: The architecture uses a standard YOLOv8 detector as its image feature extractor and a pre-trained CLIP text encoder to generate text embeddings.
- Re-parameterizable Vision-Language PAN (RepVL-PAN): The central innovation of YOLO-World is its fusion module, the RepVL-PAN. This is a modified Path Aggregation Network (PAN), a standard component in YOLO models for fusing features at different scales, that is enhanced to incorporate language information. It uses novel mechanisms like a Text-guided CSPLayer and Image-Pooling Attention to inject the text embeddings into the multi-scale visual feature pyramid produced by the YOLO backbone. This allows the text prompt to guide the feature extraction and detection process within an efficient CNN framework.
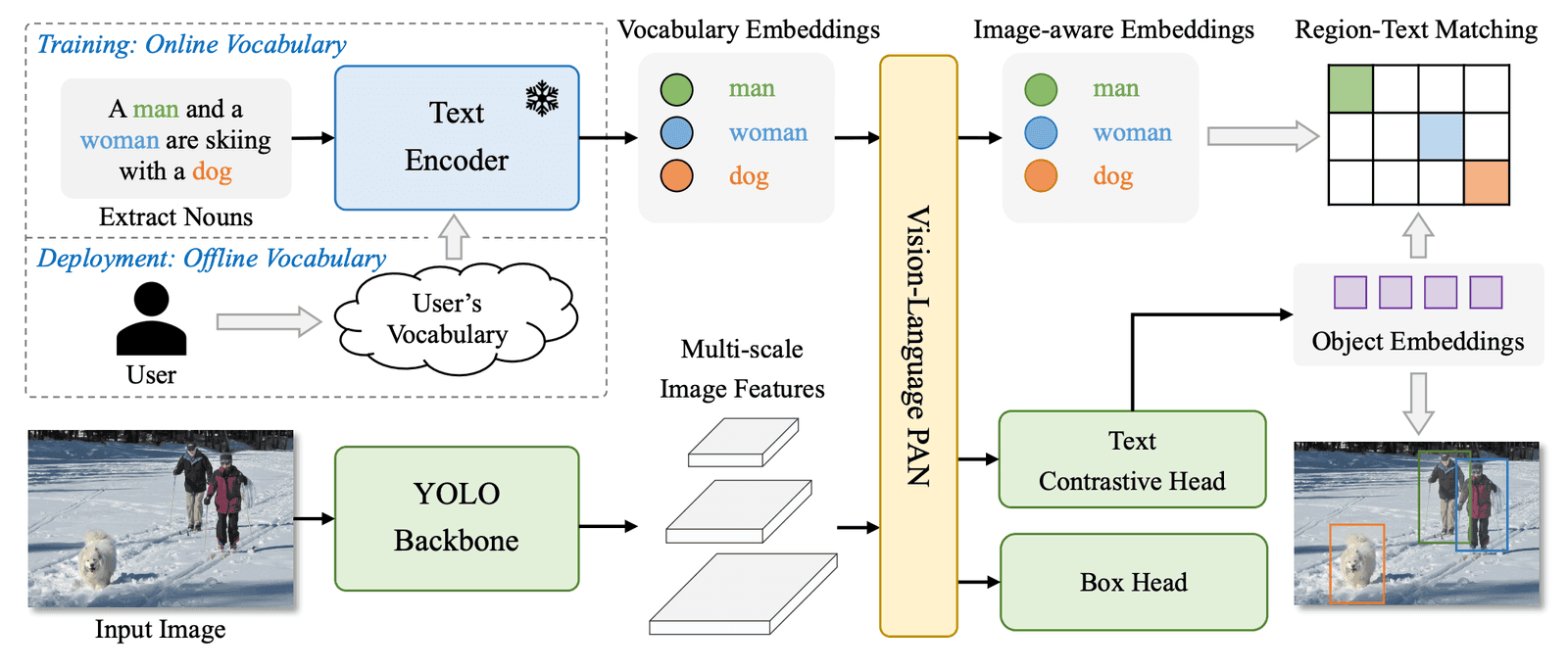
The "Prompt-then-Detect" Paradigm for Real-Time Efficiency
The most significant contribution of YOLO-World to practical OVD is its novel inference strategy, designed to eliminate the latency bottleneck of real-time text encoding.
The Problem: In a typical OVD pipeline, the text prompt is fed into a large text encoder at inference time. This encoding step adds significant latency, making it difficult to achieve real-time speeds.
The Solution: YOLO-World introduces the "prompt-then-detect" paradigm. This allows a user to define a set of custom prompts (i.e., the desired object vocabulary) offline, before deployment. These prompts are pre-encoded into a fixed set of text embeddings, creating an "offline vocabulary." During real-time inference, the model no longer needs the text encoder. It simply performs the visual detection and matches the detected objects against the small, pre-computed set of vocabulary embeddings. This re-parameterization effectively removes the text encoder from the time-critical inference loop, dramatically boosting speed and making real-time open-vocabulary detection on edge devices a practical reality.
Conclusion
These three foundational architectures showcase the diverse strategies employed to tackle OVD. OWL-ViT demonstrates a transfer learning philosophy of minimal adaptation. Grounding DINO pursues maximum accuracy through deep, multi-level architectural fusion. YOLO-World prioritizes pragmatic efficiency to bring open-vocabulary capabilities to real-time applications. The evolution of these models also reveals a key trend regarding the vision backbone: an initial reluctance to modify it (to preserve knowledge) has given way to more sophisticated approaches, including full fine-tuning on massive datasets and hybrid designs, reflecting a maturing understanding of the trade-offs between knowledge preservation and task-specific adaptation.